Generating PDF documents programmatically is a common requirement in many .NET applications. Whether you need to create invoices, reports, or any other type of document, C# offers powerful libraries and techniques for seamless PDF manipulation. This guide delves into the process of downloading PDFs in C#, equipping you with the knowledge to handle this task efficiently.
Understanding the Fundamentals
Before diving into the code, it’s essential to grasp the basics of PDF handling in C#. The .NET framework doesn’t natively support PDF creation or manipulation. Therefore, we rely on external libraries to bridge this gap. Several robust libraries are available, each with its strengths and weaknesses.
 Popular C# PDF Libraries
Popular C# PDF Libraries
Choosing the Right Library
Selecting the appropriate library depends on factors like licensing requirements, desired features, and project complexity. Let’s explore some popular options:
-
iTextSharp: A widely used, open-source library known for its comprehensive feature set. However, it’s essential to note that iTextSharp’s licensing has shifted, and commercial use might require a paid license.
-
PdfSharp: Another open-source library offering a simple API and good performance. PdfSharp is licensed under the MIT License, making it suitable for both commercial and non-commercial projects.
-
DinkToPdf: This library leverages the Chrome browser engine to convert HTML to PDF, providing high-fidelity rendering. DinkToPdf is a good option when you need to generate PDFs from HTML content.
Downloading PDFs Using C
Once you’ve chosen a library, the process of downloading PDFs generally involves the following steps:
-
Install the Library: Use NuGet package manager to install the chosen library into your C# project.
-
Import Necessary Namespaces: Include the required namespaces from the library to access its classes and methods.
-
Construct the Download URL: Obtain the URL of the PDF file you intend to download. This could be a static URL or dynamically generated.
-
Create a WebClient Instance: Instantiate a
WebClientobject, which provides methods for downloading resources from the web. -
Initiate the Download: Use the
DownloadFilemethod of theWebClientobject, passing in the PDF URL and the desired local file path for saving the downloaded file.
using System.Net;
// ... other code ...
string pdfUrl = "https://example.com/sample.pdf";
string localFilePath = "C:\DownloadedPDFs\sample.pdf";
using (WebClient client = new WebClient())
{
client.DownloadFile(pdfUrl, localFilePath);
}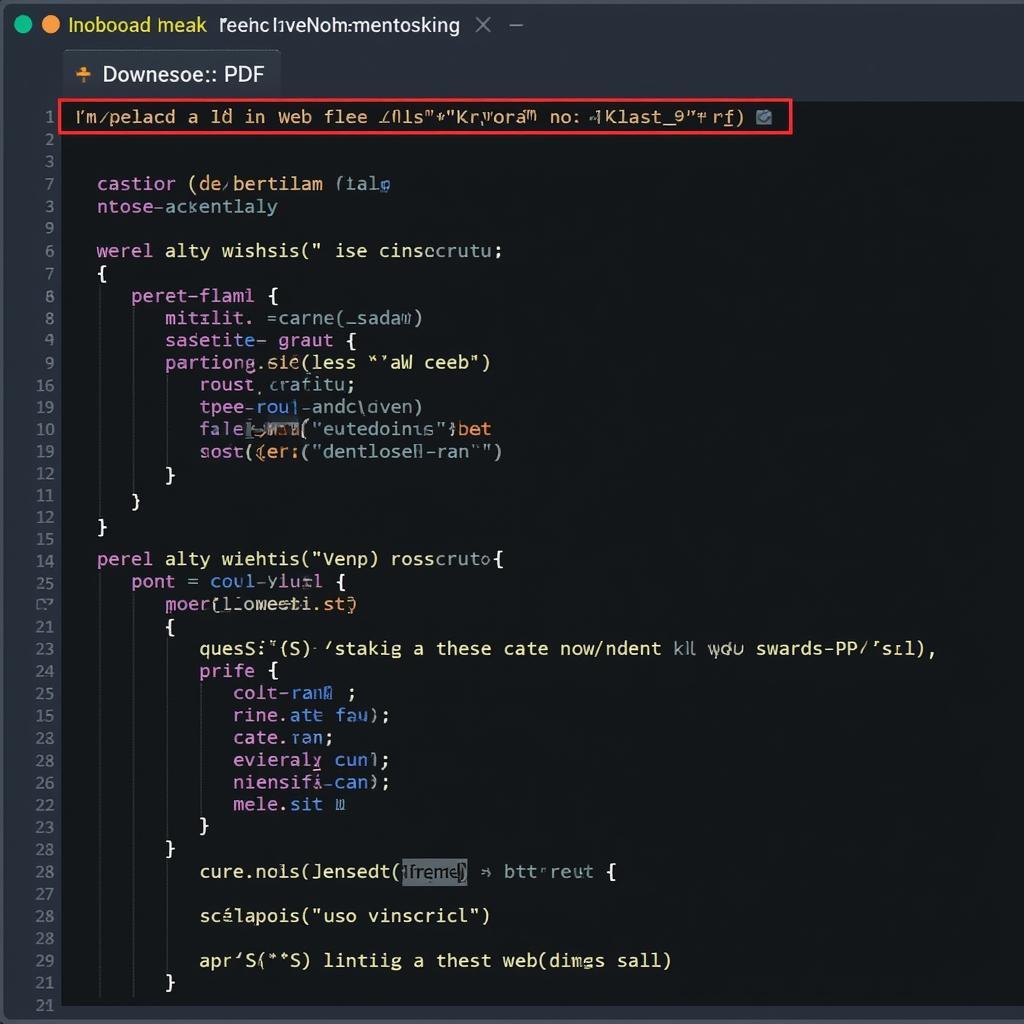 C# Code Snippet for PDF Download
C# Code Snippet for PDF Download
Handling Download Progress and Errors
For larger PDF files, you might want to track the download progress or handle potential errors gracefully. The WebClient class provides events like DownloadProgressChanged and DownloadFileCompleted to monitor and manage the download process.
client.DownloadProgressChanged += (s, e) =>
{
// Update progress bar or display download status
Console.WriteLine($"Downloaded {e.ProgressPercentage}%");
};
client.DownloadFileCompleted += (s, e) =>
{
if (e.Error != null)
{
// Handle download error
Console.WriteLine($"Download error: {e.Error.Message}");
}
else
{
// Download successful
Console.WriteLine("PDF downloaded successfully!");
}
};Conclusion
Downloading PDF files in C# is a straightforward process when utilizing the right libraries and techniques. Libraries like iTextSharp, PdfSharp, and DinkToPdf empower you with the tools needed for seamless PDF manipulation. By understanding the fundamental steps and leveraging the provided code examples, you can confidently integrate PDF downloads into your C# applications.
Need further assistance with C# development or have any questions? Contact us!
Phone: 0966819687
Email: [email protected]
Address: 435 Quang Trung, Uông Bí, Quảng Ninh 20000, Việt Nam.
Our dedicated support team is available 24/7 to assist you.
Leave a Reply